CDP Plus EL+T, ID Unification, Lake/Warehouse, Query Engine
The Blotout system operates like a CDP as the SDK layer but solves for multiple layers like EL+T, Data Unification, Airflow workflows, BI tool integration, etc.
Server CDP Tag; SDK with Consent Integration
The Blotout system is set up like a CDP. However, the SDK is set up to send all of the data to the server to decide how its processed and how it is made available to various partners - from marketing engines, CRM, etc.
The entire philosophy behind Blotout CDP tag is enablement to warehouse or lake Vs. needing a CDP proxy to do the same work.
Blotout philosophy is developed to enable enterprises to democratize their data and not have it locked in some 3P CDP.
EL + T to Unified Customer Events table
Blotout Cloud SDK, powered by Airbyte, and then serviced by the Airflow engine to ensure the data pipelines are working and making data available to the data lake or warehouse.
One of the workflows Blotout supports is enabling customer journey tables to be unified to a unified table across sites, apps, customer service departments, payment processors, etc.
This zero code workflow enables any enterprise to be able to get Big Data structure standardization to enable Customer Journey and Marketing Journey views that enable true visibility of customer lifecycles. This data in the customer event table then enables personalization via feature flags at the enterprise level.
One of the keys for the system is the ease at which you can enable 3P SaaS integrations but also your own database or your warehouse events giving a true picture of your customer journeys.
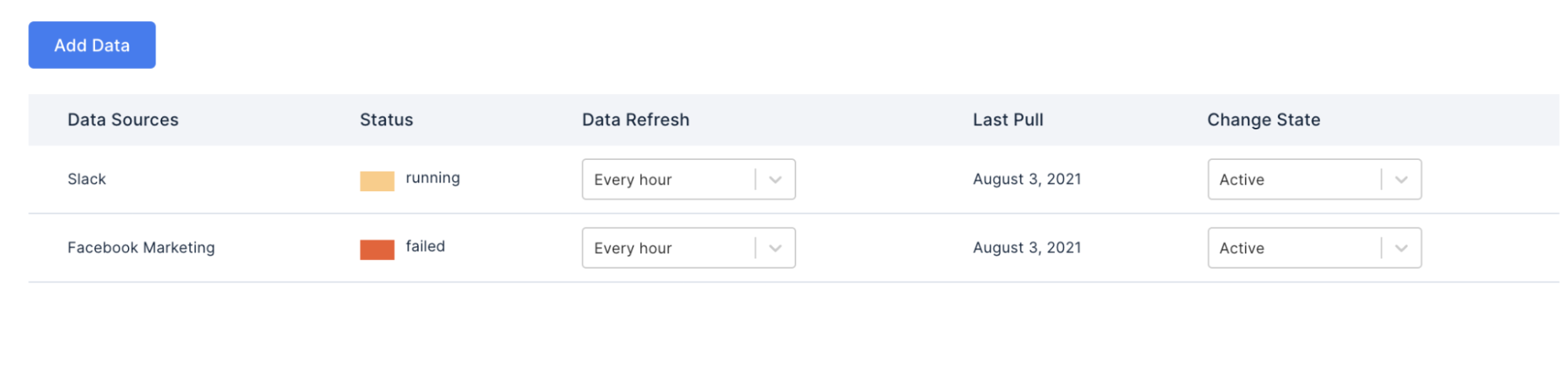
Figure: Zero code data integrations
EL+ T to Unified Cloud CRM
Similar to the Unified Customer Journey table, Blotout supports the idea of a Cloud CRM table. This table aggregates persona based traits into a single table.
This table ingests via a traits/identity object via SDK. One can set a standard traits/identity object from the SDK.
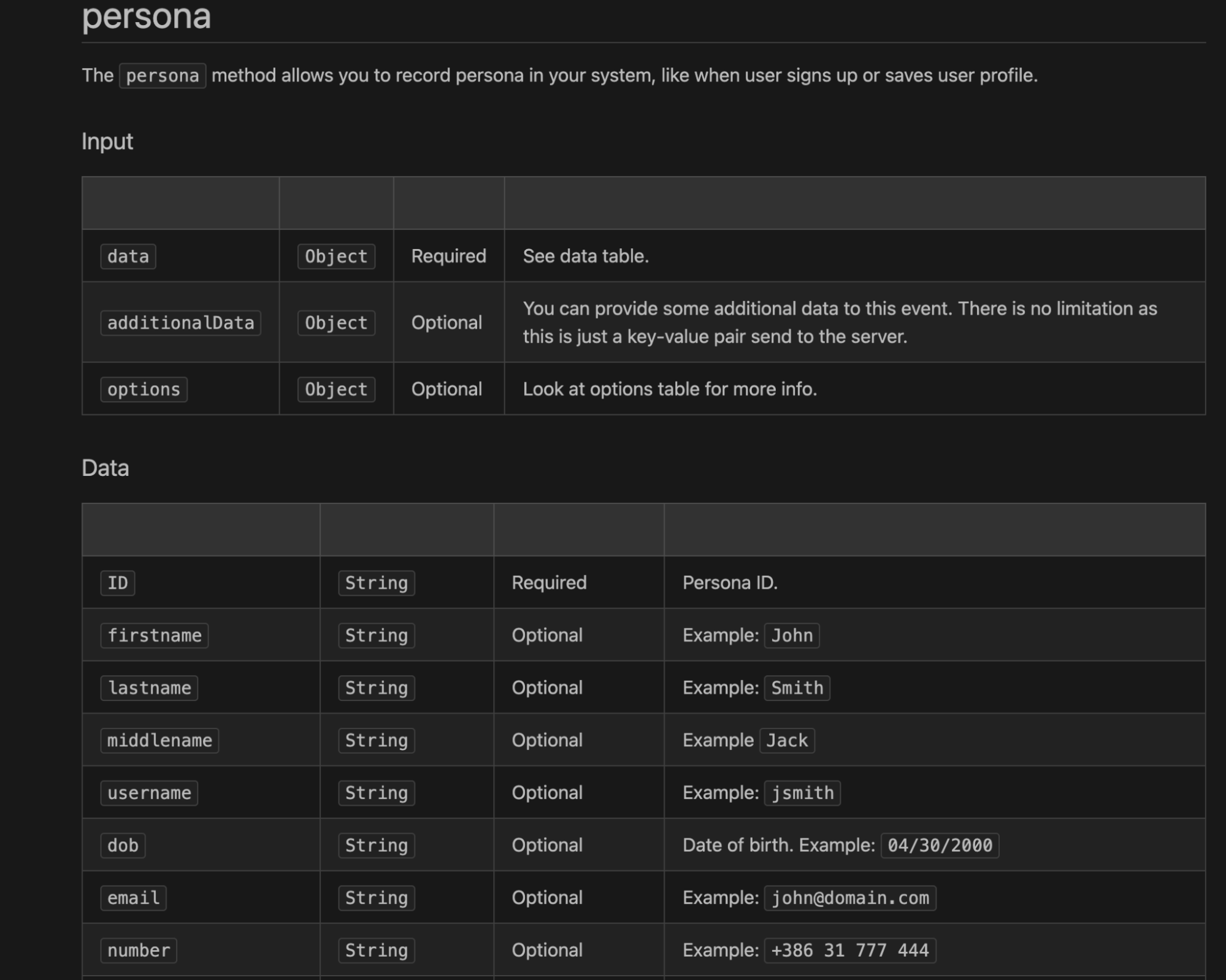
Figure: SDK Integration Event (persona, identity, traits)
Alternatively, you can pull data from any CRM source, 3P or in house and add it to the traits object.
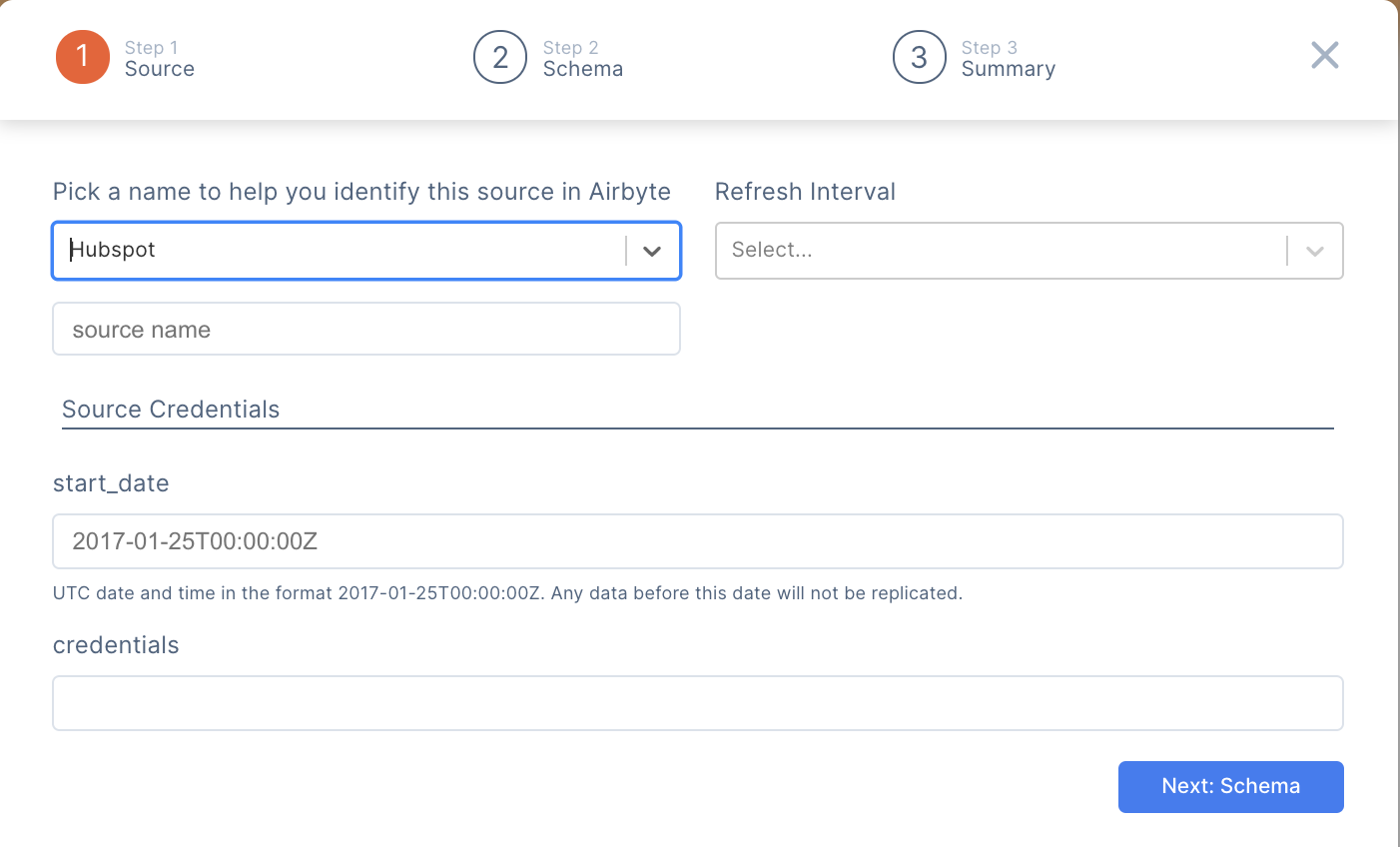
Figure: CRM Integration Server Side (persona, identity, trait)
**Feature: **This client and server CRM integration play is a significant advantage over existing CDP systems that operate as proxies (like Segment.com)
ID Mapping to a Unified Graph ID (Identity resolution)
Finally, the Blotout workflow system enables ID to be resolved across the various data sources in multiple ways.
SDK based
You can map any ID to the Graph ID table using the mapID() function on the SDK.
SDK to Server based
You can map any ID mapped via mapID() function to any column via EL + T
_Server to Server based _
You can create a new ID-MAP for a table on the server and then map another EL + T column to build a server to server map.
Store (Lake or Warehouse)
The solution comes built to store all of the normalized, extracted, transformed, and unified data to your choice of store -- a lake or a warehouse.
Query Engine
Blotout currently uses Athena for its default configuration (S3) and can be plugged into your existing warehouse or plugged directly into your favourite BI tools like Tableau or Looker.
Finally, Blotout comes with a pre-integrated BI engine with unlimited usage called Apache Superset.
Custom Applications
To ensure that every department gets access to customer journeys and cloud CRM objects that require specialized measurements and analytics not typically available via BI tools, Blotout has created custom applications for each of your departments.
BI Engine / Dashboards
Blotout query engine comes pre-integrated with Apache Superset that allows you to customize your dashboard that the Custom Applications may not support.
Blotout Widgets
Blotout supports widgets for essential but not mandatory widgets that allow you to get bits of information - say specific to your web users (pages as an example), or app users (navigation as an example). Blotout widgets use the BI engine and enable direct links into pre canned dashboards or charts.
Apache eCharts support
Blotout supports eCharts natively. This enables you to request any chart that matters to you (from hundreds) free of cost and Blotout container will make the chart available at the next upgrade.
SQL Lab
Via Apache Superset integration, the entire data lake or warehouse connected to the Blotout containers can be made available to SQL based queries that can eventually be linked to eCharts if necessary for visualization.
Data Governance
All of the data that is connected to the Blotout store systems is automatically entered into a data discovery and access system that can enable granular access management against any user or user group in the system.
The data governance system can be expanded to any other data application.