Data Pipelines
Data pipelines enable any user, specifically engineering, to be able to pull data from any source. Blotout supports more than 100 3P sources and all databases, and warehouses.
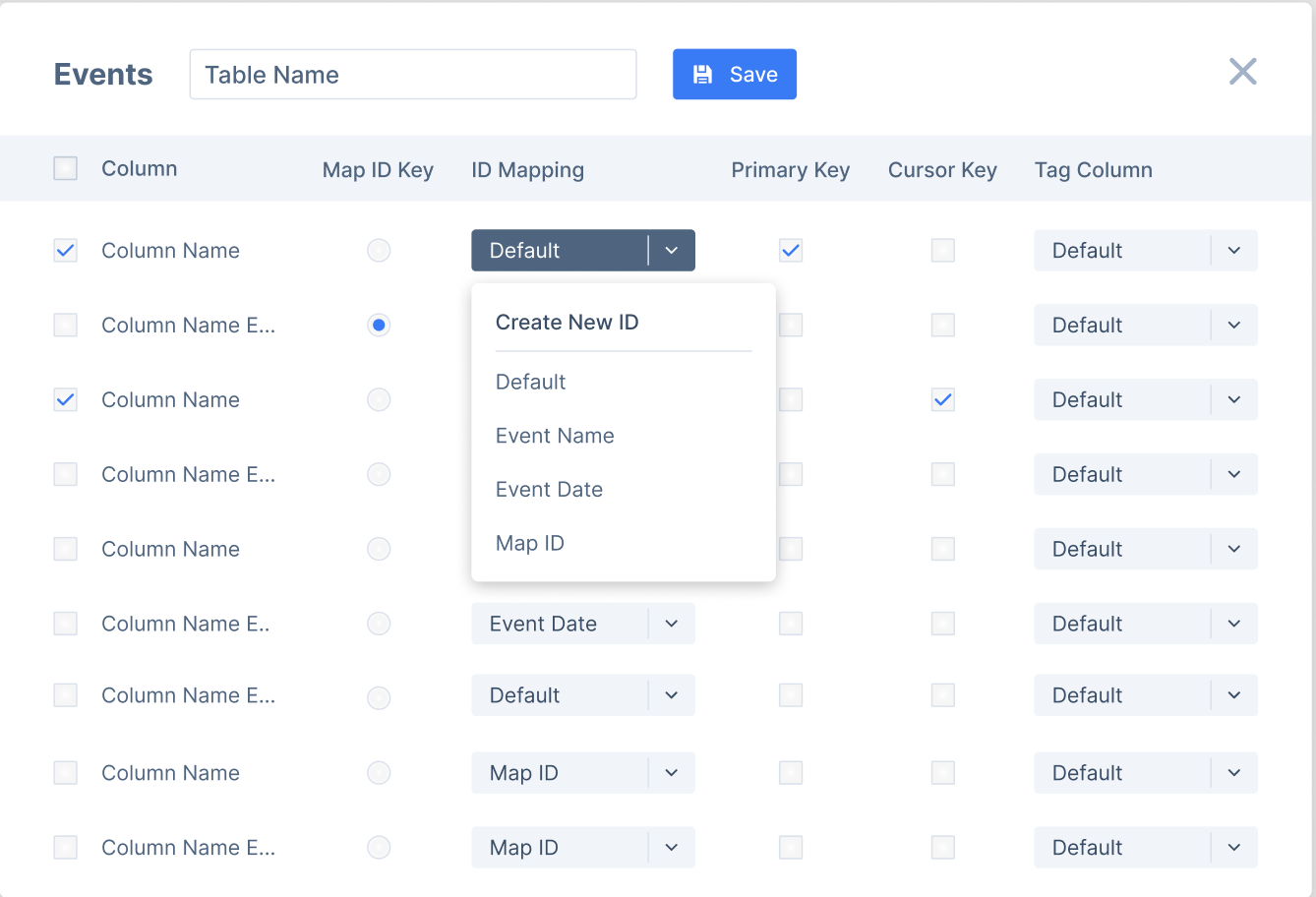
Figure: One of the key steps during EL + T workflow
With blotout’s data pipelines, the enterprise has to do no work and all of the data is piped from the source, extracted, loaded, transformed, unified, and made available in a unified data format ready to use out of the box.
In cases where measurement intelligence is supported -- a) Cost of acquisition or b) Customer Journey appends -- the data is further used to provide answers without any effort from a BI analyst saving lots of time and expenditure.
Can I pull EL + T data that can be sent to another destination?
Yes. You can choose from 20+ destinations, including all major databases, warehouses, and lakes.
Can I create a copy of a data pipeline for non Blotout purpose?
Yes. You can pretty much use the EL + T for your own purposes and port it to any destination of your choice. A managed Airflow (v2) will take care ensuring all of the data is made available in Parquet format.
Do I have to write my own transformation models?
No. Most of the 3P integrations are pre-transformed and do not require any manual intervention unless you want to override the default transformation models.
Can I write my own transformations?
Yes. We support DBT models from your own Github repository for your own custom transformations.
Is my data pull governed?
Yes. All of the fields that are high risk (PII) are demarcated as such so that the rule engine is the area of the high risk data. A policy manager can have a broad policy to prevent certain organizations from accessing such data.
Do you support the most common 3P data sources?
Yes, we can pull data from 100+ most commonly used 3P sources. If we don’t support an integration, you can email us or join our Slack channel to make a request. Alternatively, you can join our OSS repo and make a contribution. Check our integration pages to get updated.
Can I pull my transactional data from an existing warehouse, lake or database?
Yes. Unlike 3P sources where the JSON schema structure is well known, Blotout does require you to go through the entire workflows to map IDs, map data, and help define the transformations; our workflows then automatically build your DBT transformations.